はじめに
「手元に大量に学習済みの機械学習モデルがあって、管理をスプレッドシートでやっている」そんな状況ありませんか?
こんにちは。ABEJAでMLOps Engineerをしている服部です。こちらはABEJA Advent Calendar 2019の6日目の記事です。今回はABEJA Platformを使って学習済みの機械学習モデルを管理する方法を紹介します。もちろん管理にスプレッドシートを使うことは全然アリだと思いますし、それでたいていの要求は足りると思います。しかし、ABEJA PlatformはMLOps as a Serviceなので、モデルの管理だけじゃなくモデルの配信管理もできますし今後もどんどん新しいフィーチャーが追加されていくのでこの機会にどうでしょう?(ステマ)
※ちなみに、学習からABEJA Platformを使う場合は、今回の方法は非推奨です。
本題
今回の内容はこちらでソースコードを確認することができます。
前提条件
- ABEJA Platformを利用していること
- Job Definition
*1を作成していること
*1 Job Definitionとは機械学習タスクの枠です。Job Definition配下に「学習用のソースコード管理」「学習Jobの実行&結果管理」「機械学習モデル管理」があります。
Notebookの立ち上げ
このドキュメントではABEJA PlatformのNotebookを使います。ローカル環境から実行したい場合は、サンプルコードをダウンロードの上、ここから読み始めてください。
まず、トップページからJob Definition -> Notebookと下っていきます。Notebookの "Create Notebook" をクリックし、Notebookを立ち上げてください。
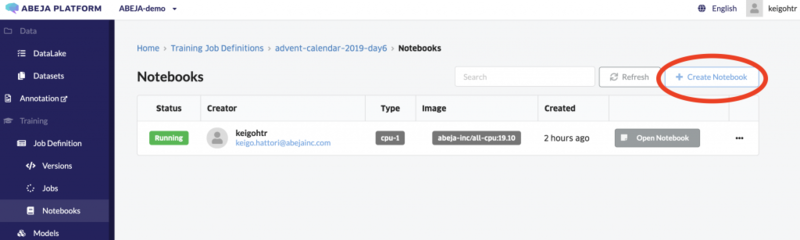 今回はJupyterLabを立ち上げました。最初にNotebookを立ち上げると、ホームディレクトリに "sample" というフォルダがあることが確認できると思います。
今回はJupyterLabを立ち上げました。最初にNotebookを立ち上げると、ホームディレクトリに "sample" というフォルダがあることが確認できると思います。
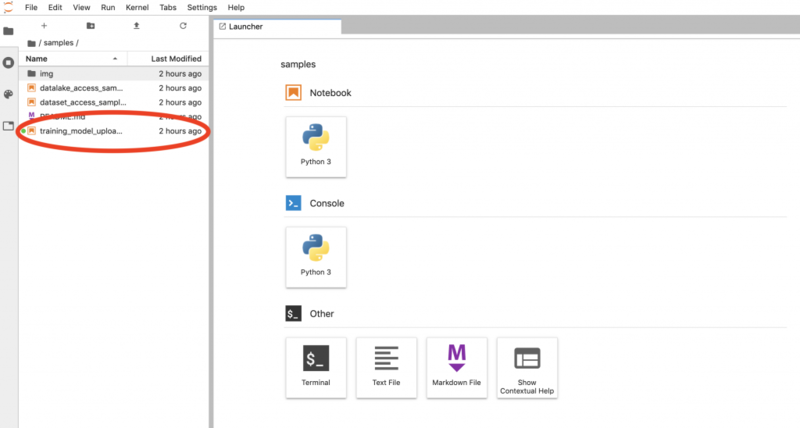
 "sample"フォルダにいくつかサンプルコードが格納されていますが、今回は
"sample"フォルダにいくつかサンプルコードが格納されていますが、今回は training_model_upload_sample.ipynb を使います。
学習済みモデルファイルをアップロードする
具体的にはサンプルコードを見ればOKですが、ここではもう少し具体的にソースコードを交えて動作を見てみます。 ローカル環境から実行したい方は、以下の環境変数をセットしてください。
| env | type | description |
|---|---|---|
| ABEJA_ORGANIZATION_ID | str | Your organization ID. |
| ABEJA_PLATFORM_USER_ID | str | Your user ID. |
| ABEJA_PLATFORM_PERSONAL_ACCESS_TOKEN | str | Your Access Token. |
ファイルのアップロードにはABEJA Platform SDKを利用します。インストールをしておいてください。まずはAPIClientを初期化します。以下を参照ください。ABEJA Platform上で実行する場合は 環境変数の TRAINING_JOB_DEFINITION_NAME が自動的にセットされますが、ローカル環境の場合は自分でセットしてください。
import os
import tempfile
from abeja.models import APIClient
api = APIClient()
_organization_id = os.environ['ABEJA_ORGANIZATION_ID']
_job_definition_name = os.environ['TRAINING_JOB_DEFINITION_NAME']
ここからが本番です。以下のソースコードを見れば一目瞭然だと思います。認証情報をセットしたら、学習済みモデルを指定してアップロードするだけです。 descriptionには好きな内容を記述できるので、メモとして使うのがおすすめです。user_parametersには学習時に指定したハイパーパラメータや日付、accuracyやlossをセットするのがおすすめです。
import random
import json
import datetime
for i in range(3):
with tempfile.NamedTemporaryFile() as tf:
tf.write(("{}".format(i)).encode('utf-8'))
tf.seek(0)
model_data = tf
loss = random.random()
acc = random.random()
c = random.random()
created_date = str(datetime.datetime.now())
user_parameters = {
'loss': f'{loss}',
'accuracy': f'{acc}',
'c': f'{c}',
'created_date': f'{created_date}'
}
description = f'{i}: {json.dumps(user_parameters)}'
parameters = {
'description': description,
'user_parameters': user_parameters
}
api.create_training_model(
organization_id=_organization_id,
job_definition_name=_job_definition_name,
model_data=model_data,
parameters=parameters
)
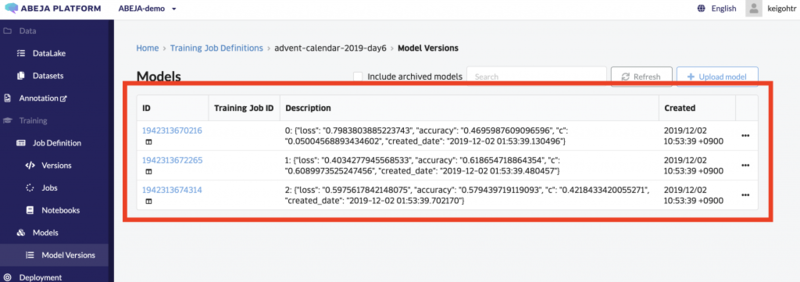
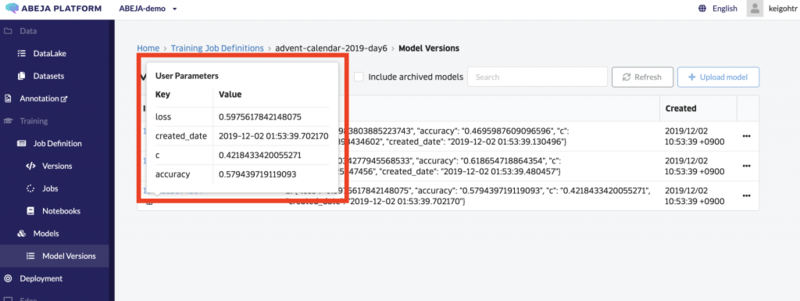
アップロードするとこんな感じでABEJA Platform上で一元管理できます。
user_parametersも確認できます。
おわりに
今回は既に手元にある大量の機械学習モデルをABEJA Platformにアップロードし、一元管理しようという試みを紹介しました。ファイルの管理だけならスプレッドシートでも出来ますので、そのあたりはお好みで良いと思います。一方で、ABEJA PlatformはMLOps as a Serviceなので、例えば学習済みモデルを配信するコードを登録しておけばコードのバージョン管理もできますし、当然http serviceで配信もできます。Batch jobとして実行することもできます。将来的にはABテストやモデルの性能評価機能も盛り込んでいくので、この機会にABEJA Platformのご利用はいかがでしょうか?(再三に渡るステマ)