はじめに
deeplearning4jではAdamなどの主要なUpdaterは大体使えますが、Updater毎に設定できるパラメータが違うので、メモも兼ねてまとめておきます。

参考情報
- deeplearning4j公式
- deeplearning4j公式githubその1
- deeplearning4j公式githubその2
- AdaGrad, RMSProp, AdaDelta, Adam, SMORMS3
Updater
数式はプラグインを入れるのがめんどくさかったので上記のdeeplearning4j公式で使っている画像を拝借しました(駄目だったら教えてください)。以降では、「数式」「dl4jで使えるパラメータと推奨値」「サンプルコード」と言うかたちで説明します。
Adagrad

| 数式 | dl4j | 推奨 |
|---|---|---|
| α | learningRate | 1e-1 or 1e-2 |
| ε | epsilon | 1e-6 or 1e-8 |
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(1)
.updater(Updater.ADAGRAD)
.learningRate(1e-1)
.epsilon(1e-6)
.list()
.layer(0, new GravesLSTM.Builder()
.nIn(numInputs).nOut(numInputs)
.activation("softsign")
.build())
.layer(1, new RnnOutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.MCXENT)
.activation("softmax")
.nIn(numInputs).nOut(numOutputs)
.build())
.pretrain(false).backprop(true).build();
RMSProp
![]()
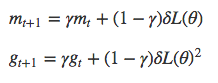
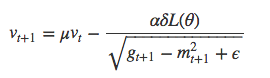
![]()
| 数式 | dl4j | 推奨 |
|---|---|---|
| α | learningRate | 1e-1 or 1e-3 |
| γ | rmsDecay | 0.95 or 0.90 |
| ε | epsilon | 1e-8 |
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(1)
.updater(Updater.RMSPROP)
.learningRate(1e-1)
.rmsDecay(0.90)
.epsilon(1e-8)
.list()
.layer(0, new GravesLSTM.Builder()
.nIn(numInputs).nOut(numInputs)
.activation("softsign")
.build())
.layer(1, new RnnOutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.MCXENT)
.activation("softmax")
.nIn(numInputs).nOut(numOutputs)
.build())
.pretrain(false).backprop(true).build();
AdaDelta

| 数式 | dl4j | 推奨 |
|---|---|---|
| γ | rho | 0.95 |
| ε | epsilon | 1e-8 |
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(1)
.updater(Updater.ADADELTA)
.rho(0.95)
.epsilon(1e-8)
.list()
.layer(0, new GravesLSTM.Builder()
.nIn(numInputs).nOut(numInputs)
.activation("softsign")
.build())
.layer(1, new RnnOutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.MCXENT)
.activation("softmax")
.nIn(numInputs).nOut(numOutputs)
.build())
.pretrain(false).backprop(true).build();
ADAM

| 数式 | dl4j | 推奨 |
|---|---|---|
| α | learningRate | 1e-3 |
| γ1 | adamMeanDecay | 0.9 |
| γ2 | adamVarDecay | 0.999 |
| ε | epsilon | 1e-8 |
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(1)
.updater(Updater.ADAM)
.learningRate(1e-3)
.adamMeanDecay(0.9)
.adamVarDecay(0.999)
.epsilon(1e-8)
.list()
.layer(0, new GravesLSTM.Builder()
.nIn(numInputs).nOut(numInputs)
.activation("softsign")
.build())
.layer(1, new RnnOutputLayer.Builder()
.lossFunction(LossFunctions.LossFunction.MCXENT)
.activation("softmax")
.nIn(numInputs).nOut(numOutputs)
.build())
.pretrain(false).backprop(true).build();